
While developing web/console applications in .NET we may need to read pdf file data using C#, so in this article, I am going to provide you a working code sample and step by step instructions to create a console app that reads PDF file data and show it in a console app, using iTextSharp.
Step 1: Create a new console app in your Visual Studio, by navigating to File-> New -> Project -> Select "Console APP(C#)" from the right pane(you can search it also on top righ search bar) -> Give a name & click OK
Step 2: As we will be using iTextsharp to readh PDF file in C#, let's install iTextSharp in our Console app using Nuget package manager console.
Navigate to Tools->Nuget Package manager -> Select "Manage Nuget packages for solution..."
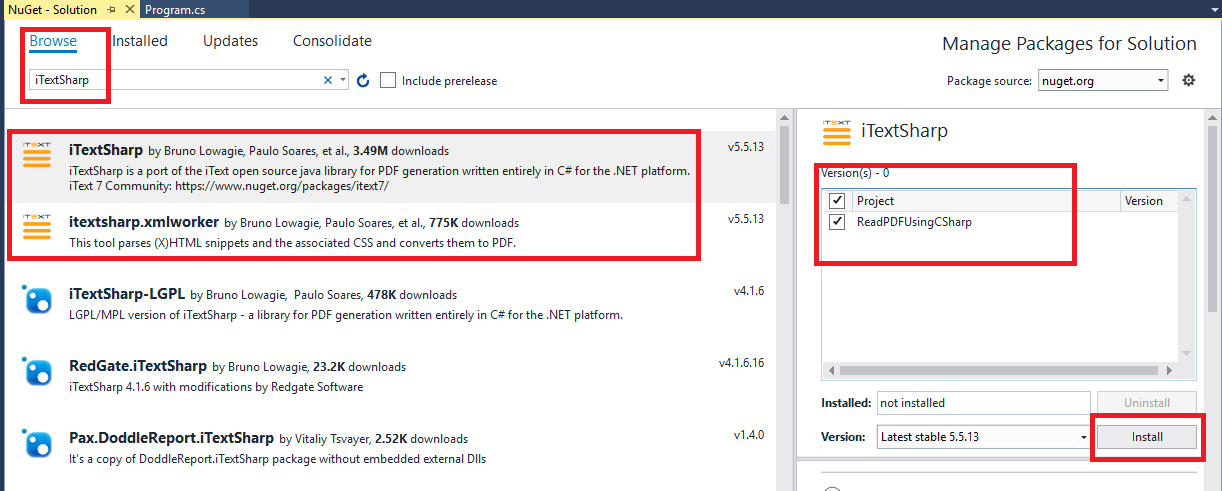
Step 3: Now, here is our main code which read each line of pdf file using iTextSharp and convert it into string
public static string ExtractTextFromPdf(string path)
{
using (PdfReader reader = new PdfReader(path))
{
StringBuilder text = new StringBuilder();
for (int i = 1; i <= reader.NumberOfPages; i++)
{
text.Append(PdfTextExtractor.GetTextFromPage(reader, i));
}
return text.ToString();
}
}So, the complete code in C# for the console app will be as below
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
using System;
using System.Text;
namespace ReadPDFUsingCSharp
{
class Program
{
static void Main(string[] args)
{
var ExtractedPDFToString
= ExtractTextFromPdf(@"C:\Users\CT\Desktop\pdf-sample.pdf");
Console.WriteLine(ExtractedPDFToString);
}
public static string ExtractTextFromPdf(string path)
{
using (PdfReader reader = new PdfReader(path))
{
StringBuilder text = new StringBuilder();
for (int i = 1; i <= reader.NumberOfPages; i++)
{
text.Append(PdfTextExtractor.GetTextFromPage(reader, i));
}
return text.ToString();
}
}
}
}
Where "C:\Users\CT\Desktop\pdf-sample.pdf" is the location of the sample pdf which we have used, here is the sample pdf screenshot

Here is the output of the console app
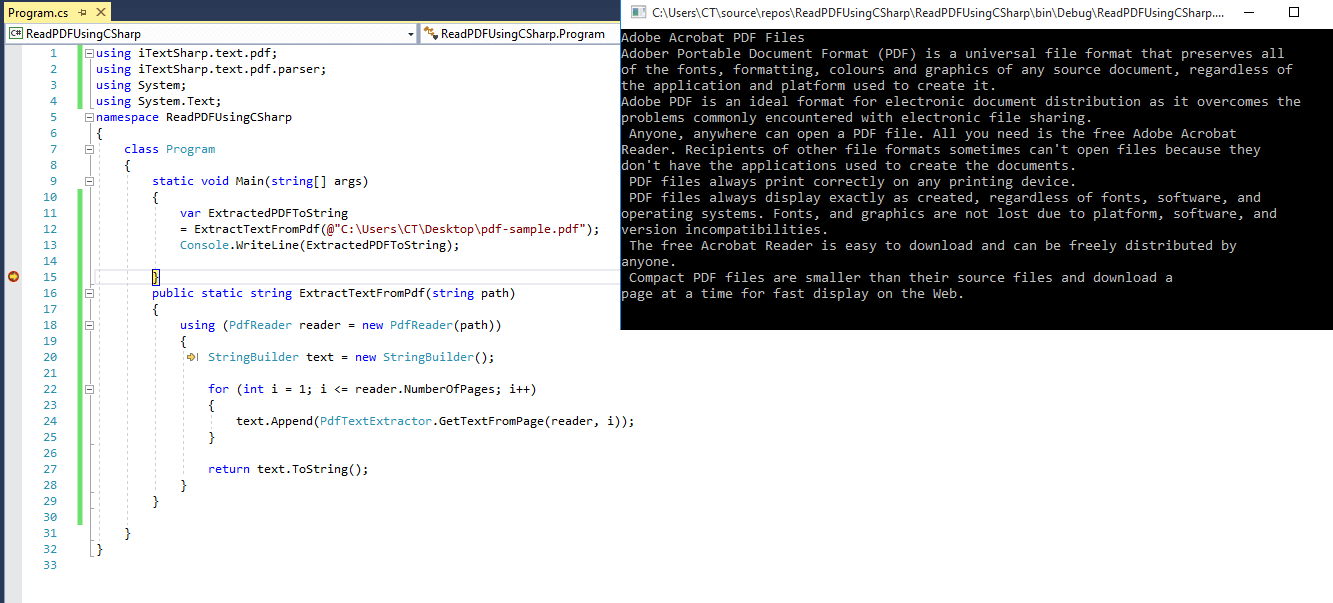
In the above code, we are using PdfTextExtractor to get text from the page and append it in StringBuilder text, once we have fetched all the pages, we print it in console.
That's it, we are done, you can download code sample.
Reading PDF in C# (.NET Core) using PDFPig
PdfPig is an Apache 2.0 licensed library started as an attempt to port the Java PDFBox project to C#.
It allows users to read and extract text and other content from PDF files. In addition the library can be used to create simple PDF documents containing text and geometrical shapes.
So, first you would have to install PDFPig Nuget Package in your .NET Core project.
Install-Package PdfPigIt has a dependency on System.ValueTuple for old .NET frameworks like 4.5 or 4.7, so if you are installing it in these framework, also use System.ValueTuple.
Once you have installed the NuGet package, you can use the C# code as below to read the pdf in .NET Core
using (var pdf = PdfDocument.Open(@"C:\Users\CT\Desktop\pdf-sample.pdf"))
{
foreach (var page in pdf.GetPages())
{
// Either extract based on order in the underlying document with newlines and spaces.
var text = ContentOrderTextExtractor.GetText(page);
// Or based on grouping letters into words.
var otherText = string.Join(" ", page.GetWords());
// Or the raw text of the page's content stream.
var rawText = page.Text;
Console.WriteLine(text);
}
}
Each page gives you access the letters and their exact position on the page
You may also like to read:
Read file in C# (Text file .NET and .NET Core example)
Generate Class from XSD in C# (Using CMD or Visual Studio)
Email Address Validation in C# (With and without Regex)
Create Web-API in Visual Studio 2022 Step by Step
Convert String to List in C# and string array to list
 Buy us a coffee
Buy us a coffee Become a Patron
Become a Patron