
In previous article, I have mentioned how to read pdf in C# and how to read excel file in C#, in this article, I have provided step by step console application example to read or extract text from image in C# using Tesseract OCR in .NET Framework.
Step 1: Create a new Console Application in your Visual Studio (I am using VS 2017), by navigating to File -> New -> Project and Select "Console Application" from right-pane and "Windows Desktop" from left-pane, name it (ReadFromImageCsharp) and click Ok.
Step 2: As mentioned above, we will be using Tesseract OCR for extracting text from image, so we will be installing NuGet package for Tesseract OCR, for this, navigate to Tools -> NuGet Package Manager -> Manage Nuget packages for Solution -> Select "Browse" tab and search for "Tesseract", select the package with name "Tesseract" and Install it in your project.
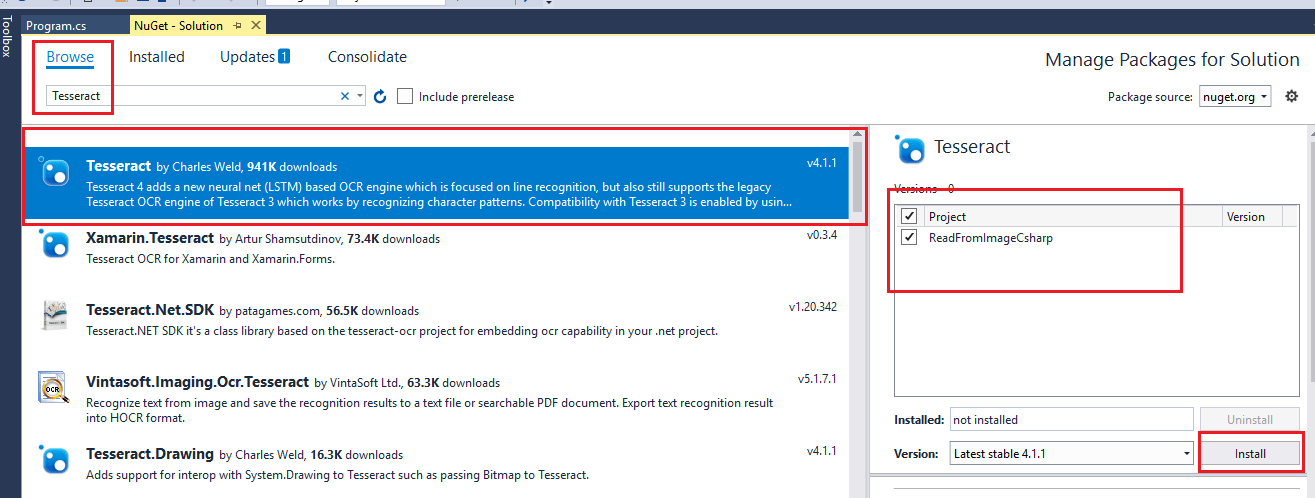
Step 3: Now, you need to download langauge file for Tesseract, and place it in folder "\tesseract" in your project solution, I will be using "English" language only, so I have downloaded only eng.traineddata from https://github.com/tesseract-ocr/tessdata_fast/blob/main/eng.traineddata
You can download other language traineddata from https://github.com/tesseract-ocr/tessdata_fast
So,location of above file in my project looks like this
C:\Users\Acer\Source\Repos\ReadFromImageCsharp\ReadFromImageCsharp\tessdataStep 4: Once you have Installed above Nuget package, then navigate to Program.cs and use the below code
using System;
using Tesseract;
namespace ReadFromImageCsharp
{
class Program
{
static void Main(string[] args)
{
//location to testdata for eng.traineddata
var path = @"C:\Users\Acer\Source\Repos\ReadFromImageCsharp\ReadFromImageCsharp\tessdata";
//your sample image location
var sourceFilePath = @"F:\sample\sample.png";
using (var engine = new TesseractEngine(path, "eng"))
{
engine.SetVariable("user_defined_dpi", "70"); //set dpi for supressing warning
using (var img = Pix.LoadFromFile(sourceFilePath))
{
using (var page = engine.Process(img))
{
var text = page.GetText();
Console.WriteLine();
Console.WriteLine("---Image Text---");
Console.WriteLine();
Console.WriteLine(text);
}
}
}
}
}
}
That's it, we are done, once you will build the above code and run, then you will see output like below
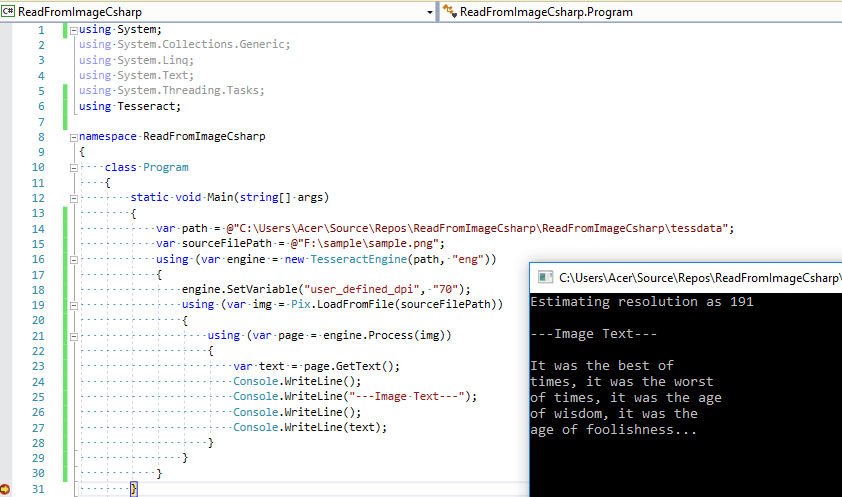
In the above code, we have provided path to testdata for eng.traineddata, so Tesseract OCR can use English language, traineddata to convert image into text.
If you are converting Image into text for any other language, then you would have to use traineddata for it and also specify language for it, when initiating tesseract engine.
Once we have initialized enginer, we can load source file path(image file path) and then using .GetText(), we can fetch text from image.
As you can see from above image Console Output, we were able to get only Text of image using tesseract in C#.
This library is under Apache License 2.0, that means you can use it for free.
You may also like to read:
Convert PDF to Image in C# (Console Application Example)
AWS vs DigitalOcean (Which is better? with Price Comparison)
 Buy us a coffee
Buy us a coffee Become a Patron
Become a Patron